

一、茶树基因型数字化
基因型又称遗传型,是某一生物个体全部基因组合的总称。基因型数字化鉴定能够高通量准确鉴定基因型,是解析重要农艺性状相关遗传信息的基础,是茶树种质资源研究的必然发展趋势。
1.基因组组装
2017—2018年,利用二代测序技术进行基因组序列组装的云抗10号和舒茶早基因组草图陆续公布。其中,云抗10号组装得到的基因组大小为3.02Gb,包括了36951个注释编码蛋白;舒茶早基因组大小为3.14Gb,包含33932个注释编码蛋白。
随着三代测序和Hi-C技术的成熟,近些年公布了多个染色体水平的茶树基因组。利用Hi-C技术将舒茶早基因组草图提升到了染色体水平,scaffoldN50从原来的1.4Mb提升到218.1Mb,基因组中94.7%的序列被定位到了15条染色体中。利用PacBio和Hi-C技术,构建了染色体级别的舒茶早基因组,其大小为2.94Gb,具有50525个注释编码蛋白。利用PacBio和Hi-C技术获得了茶树碧云染色体级别的基因组图谱,其大小为2.92Gb,scaffoldN50为195.68Mb。公布了龙井43的染色体级别基因组序列,其基因组大小为3.26Gb,编码33556个注释蛋白。华中农业大学的研究团队公布了云南省古茶树DASZ基因组序列,该基因组为3.11Gb,编码33021个注释蛋白。福建农林大学和中国农业科学院基因所发布了黄棪和铁观音2个品种染色体级别的基因组序列。黄棪茶树基因组为2.94Gb,包含43779个蛋白质编码基因。铁观音茶树基因组大小为3.06Gb,包含了42825个蛋白质编码基因。
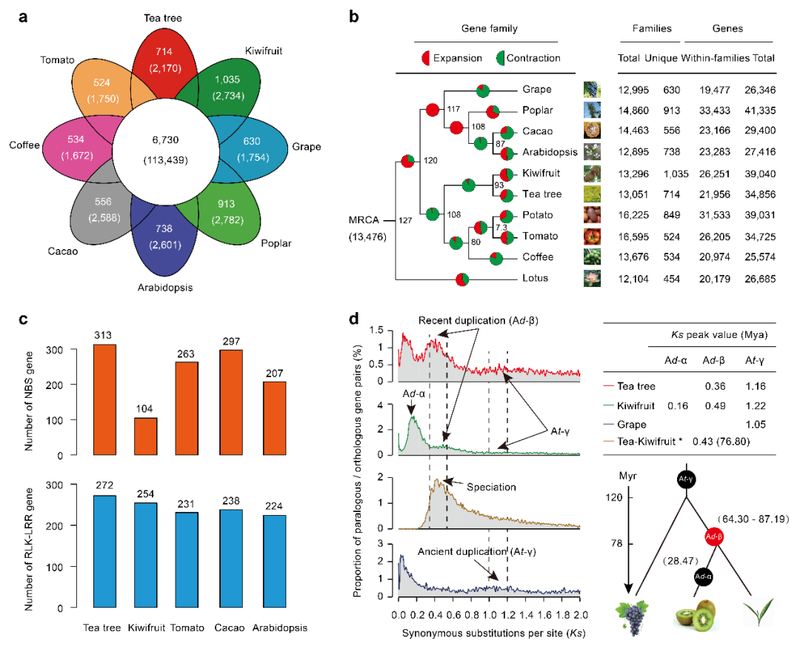
茶树基因组和基因家族的进化

‘龙井43’基因组特征和质量评估结果
2.单核苷酸多态SNP分型
全基因组重测序能够基于SNP实现全基因组水平上的基因型分型,近年来逐步开始应用于茶树种质资源的鉴定。对来自中国、老挝、俄罗斯、阿塞拜疆和伊朗的81个栽培型和野生型茶树进行重测序,共检测到6252201个SNP位点,基于基因型进行了系统发育分析,将这些资源分为3个类群。利用重测序技术对来自世界各地的139份茶树种质资源进行分析,得到了21887万个SNP位点的基因型分型结果,平均1kb就有67个SNP位点。对190份茶树资源进行重测序分析,共鉴定到9407149个SNP位点,得到相关基因型分型结果,并进行了茶树种质资源的系统发育分析。对金萱和云茶1号及其96个F1代进行了全基因组重测序,利用8956个SNP位点的基因型数字化结果构建了遗传图谱。
简化基因组测序是利用限制性内切酶对DNA进行酶切,并对酶切片段两端序列进行高通量测序,通过鉴定获得的SNP信息进行基因分型,是一种快速、简单、低成本的基因型数字化方法。基于迎霜、北跃单株及其148个F1子代利用SLAF-seq技术开发出了6042个SNP标记,并以此建立了首张茶树SNP遗传图谱。基于龙井43、白毫早及其327个F1代使用2bRAD测序技术获得了13446个SNP标记,构建了高密度遗传图谱,并得到了27个与儿茶素相关的QTL位点。利用简化基因组技术对59份茶组植物进行测序,得到了248772个高质量SNP位点的分型结果,随后对这些SNP位点进行了主成分分析、遗传结构分析和基因流分析,结果发现大厂茶与疏齿茶有遗传结构上的差异,且证明茶组植物种内亲缘关系受其地理来源的直接影响。对龙井43、白鸡冠及其杂交产生的198个F1个体进行了简化基因组测序,构建了包含2688个SNP标记的遗传图谱,并根据2年的氨基酸数据进行了QTL分析,最终得到了4个与氨基酸含量相关的QTL位点。
转录组测序能够鉴定基因表达区的SNP位点,进行SNP分型。完成了古茶树DASZ染色体级别的基因组组装,并在此基础上与217份不同茶树种质资源的转录组数据进行比较。结果表明,81.1%的DASZ注释基因被覆盖SNPs,其中4个SNP与ECG的含量显著关联。利用139份中国茶树品种的转录组数据鉴定到了925854个高质量的SNP,并将139份茶树品种分为5个类群,发现每个类群各有特异代谢物积累和基因表达差异,其中阿萨姆茶具有丰富的黄酮类化合物积累。
二、茶树表型数字化
表型组学旨在集成自动化平台装备和信息化技术手段,可以系统、高效地获取表型信息,以实现植物表型的数字化精准鉴定。表型组学常常构建一些表型检测平台,搭载图像、点云、光谱、红外、X射线等技术来快速高效地数字化采集植物多尺度的大量表型数据,目前已在玉米、小麦、大豆等较多作物上应用。
表型组学在茶树种质资源鉴定评价中的应用还处于起步阶段,一些简单的技术在茶树叶片形态特征和农艺性状相关的表型上开展了应用。利用Photoshop对茶树的叶面积进行了测量,并与叶面积的经验公式进行对比,发现计算机测定的结果更加准确。利用Photoshop对茶树新梢的颜色和成熟叶的叶面积进行了测定,并对其中的相关参数进行了分析。但是这两项工作都是基于Photoshop软件进行研究,导致关于图像处理的操作有限,自由度小,同时工作效率也受到限制,难以处理大批量的茶树叶片图像。随着数字化研究的不断深入,像Python、R、MATLAB等编程语言因具有批量处理、速度快、应用面广等优点,渐渐成为了进行茶树表型数字化处理的主流工具。随着无人机技术的发展,利用无人机对茶树进行表型分析成为了新的发展趋势。利用3种模型分别通过无人机拍摄的茶园多光谱图片对茶树的氮、茶多酚和氨基酸的含量进行评估。结果表明,SVM模型对于预测氮和茶多酚的含量最佳;PLSR模型预测氨基酸的含量是最佳的,同时证明空中预测结果与地面测量结果一样可靠,这为茶树种质资源的精准评价提供了技术支持。
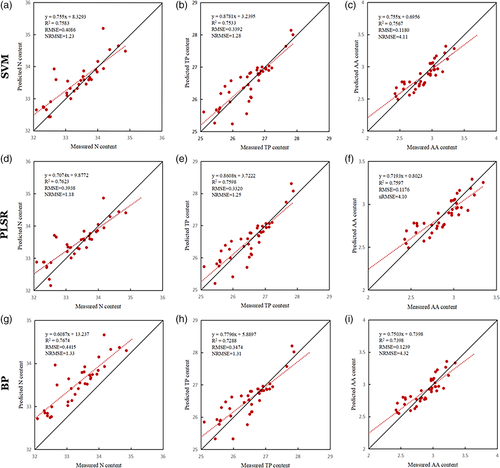
SVM、PLS和BP模型被用于验证,并测量和预测的值进行比较和分析:(a)使用支持向量机来预测氮(N);(b)利用SVM预测茶多酚(TP);(c)利用SVM预测氨基酸(AA);(d)PLS回归预测N;(e)PLS回归预测TP;(f)PLS回归预测AA;(g)BP预测N;(h)利用BP预测TP;(i)利用BP预测AA。
目前,茶树种质资源表型数字化的应用主要体现在基于分类器结合图像特征对茶树种质资源识别的方面。提取了17份茶树种质资源的14个图像特征,并基于图像特征进行了遗传多样性分析,并利用人工神经网络对茶树品种进行了预测。通过茶树鲜叶图像对10个茶树品种进行了识别。除了利用形态特征、纹理特征及颜色特征外,还使用多重分形特征来对叶片进行描述,并用6种分类器同时建模比较分类精度。结果表明,SVM和随机森林法的建模对茶树种质资源的分类精度较高,能达到90%左右。在利用图像特征识别武夷岩茶的方面研究较多,2018年对SVM分类器的内核进行了优化后,以提取的14个形状和纹理图像特征为基础,对水仙和肉桂这2份茶树资源进行识别,准确率高达91%;2019年利用3种分类器通过灰度共生矩阵下的纹理特征对黄观音、瑞香、丹桂和奇兰4个品种的茶鲜叶进行识别,其识别准确率在80%左右,且结果证明KNN分类器的识别率最高;2020年利用整体与局部信息融合的CNN模型结合茶树叶片的整体特征和局部特征对9个武夷岩茶茶树品种进行识别,识别率达到96.69%。
三、茶树数字化管理与利用
随着表型组和基因组的快速发展,大量种质资源的数字化表型和基因型被鉴定,这使得很多重要的农艺性状被揭示。但是由于数据量大,导致共享利用不便,阻碍了茶树重要农艺性状的分子解析。随着互联网技术的快速发展,种质资源信息数据库的搭建可以快速实现数字化管理与利用。中国农业科学院茶叶研究所利用生物信息技术和互联网技术建设了茶树种质资源基因组变异大数据分析平台。目前平台已经整合超过7000多万个基因组变异位点、808份茶树资源的基因型数据、464种代谢物的表型数据和430682个基因型-表型关联位点。平台主要用于茶树种质资源基因组变异的大数据在线分析,能够根据基因组位置、基因信息、材料比较、基因或变异编号等不同的策略检索基因组SNP和InDel。通过该平台还能够实现茶树种质资源的代谢表型查询及GWAS分析,快速挖掘性状相关的SNP和InDel位点。此外,平台还整合了在线Blast、序列提取、引物设计、群体遗传分析等工具,为茶树种质资源的数字化利用与共享提供了一个用户友好型平台。安徽农业大学构建了茶树信息档案数据库(TPIA),以舒茶早基因组图谱为框架,整合了基因组信息、转录组、代谢组等数据。平台还集成了功能富集分析、相关性分析、引物设计、序列比对等工具,有助于组学数据的数字化利用。南京农业大学构建了茶树基因组数据库(TeaPGDB),整合了已完成组装的各个基因组数据,方便科研人员进行利用分析。此外,一些转录组相关的数据库网站也陆续被开发,如TeaCoN、TeaAS等。茶树种质资源数字化管理与利用能有效促进茶树种质资源的保护、利用与共享,为茶树系统演化研究、关键性状解析、品种改良等提供了坚实的基础。

茶树信息档案数据库(TPIA)
四、展望
1.组学技术
未来,组学技术将在茶树种质资源的数字化精准鉴定方面不断深入,利用基因组学、转录组学、表观组学、蛋白组学、代谢组学、表型组学等技术手段,对茶树种质资源进行高通量、多维度、精准化的鉴定评估。与基因组学技术相比,表型组学技术在茶树种质资源中的应用还比较落后,这阻碍了茶树种质资源的精准评价和深入挖掘进程。针对茶树种质资源的特性,加强茶树表型鉴定设施平台的建设,开发对应的数字化鉴定方法,从而提升茶树种质资源规模化、批量化、精准化鉴定评价的基础和条件。
2.多组学联合分析
伴随着大量茶树种质资源被数字化精准鉴定,多组学联合分析将成为实现茶树种质资源创新利用的必然途径。通过基因组学和生物信息学等技术手段,利用多组学联合分析系统深入挖掘基因型、表型和环境型之间的内在关联,研究茶树表型对遗传信息和环境变化的响应机制。同时,结合分子生物学、遗传育种学、生物化学、合成生物学等技术,深入解析茶树重要农艺性状的分子机理和遗传基础,为茶树种质资源的创新利用提供坚实基础,并加速茶树品种改良进程。
3.数字化利用与共享
茶树种质资源数字化鉴定评估产生的数据量庞大、标准不一,导致共享利用不便,阻碍了其生物数据的有效利用。为了增加不同数据集之间的可比性,必须通过科学的分类、统一的描述规范和对茶树种质资源的基因组、转录组、代谢组、表型组等组学数据进行标准化处理和评价。利用大数据和互联网技术,整合茶树种质资源多组学数据,开发友好型在线分析工具,创建资源共享利用平台,加快数字化种质资源的利用效率,推动整个茶科学的进步与发展。
本文节选自《中国茶叶》2022年第4期,P1-7,《茶树种质资源数字化研究及展望》,作者:陈琪予,陈亮,陈杰丹。
信息贵在分享,如涉及版权问题请联系删除










